
diff options
| author | lukeflo | 2025-10-15 08:50:54 +0200 |
|---|---|---|
| committer | lukeflo | 2025-10-15 08:50:54 +0200 |
| commit | 7d59b6c816fa81c13cdf8348a2e7db0076015cd1 (patch) | |
| tree | 06e863cc52411cf041ca0d118c1334c7d3e3bac2 | |
| parent | 34170cfa62df5443a0d8675106c553efec035687 (diff) | |
| parent | db882623358d9141927bd31f6825472f2cdca4b6 (diff) | |
| download | bibiman-7d59b6c816fa81c13cdf8348a2e7db0076015cd1.tar.gz bibiman-7d59b6c816fa81c13cdf8348a2e7db0076015cd1.zip | |
Merge pull request 'implement basic citekey formatting' (#58) from format-citekeys-#55 into main
Reviewed-on: https://codeberg.org/lukeflo/bibiman/pulls/58
| -rw-r--r-- | CITEKEYS.md | 246 | ||||
| -rw-r--r-- | Cargo.lock | 8 | ||||
| -rw-r--r-- | Cargo.toml | 4 | ||||
| -rw-r--r-- | Cross.toml | 6 | ||||
| -rw-r--r-- | README.md | 20 | ||||
| -rw-r--r-- | src/bibiman.rs | 109 | ||||
| -rw-r--r-- | src/bibiman/bibisetup.rs | 108 | ||||
| -rw-r--r-- | src/bibiman/citekeys.rs | 398 | ||||
| -rw-r--r-- | src/bibiman/citekeys/citekey_utils.rs | 342 | ||||
| -rw-r--r-- | src/bibiman/sanitize.rs | 10 | ||||
| -rw-r--r-- | src/bibiman/sanitize/optimized_sanitize.rs | 28 | ||||
| -rw-r--r-- | src/cliargs.rs | 173 | ||||
| -rw-r--r-- | src/config.rs | 130 | ||||
| -rw-r--r-- | src/main.rs | 38 | ||||
| -rw-r--r-- | tests/test-config.toml | 19 |
15 files changed, 1430 insertions, 209 deletions
diff --git a/CITEKEYS.md b/CITEKEYS.md new file mode 100644 index 0000000..828e557 --- /dev/null +++ b/CITEKEYS.md @@ -0,0 +1,246 @@ +# Formatting Citekeys<a name="formatting-citekeys"></a> + +<!-- mdformat-toc start --slug=github --maxlevel=6 --minlevel=1 --> + +- [Formatting Citekeys](#formatting-citekeys) + - [Settings](#settings) + - [Building Patterns](#building-patterns) + - [Ignore Lists and Char Case](#ignore-lists-and-char-case) + - [General Tipps](#general-tipps) + - [Examples](#examples) + +<!-- mdformat-toc end --> + +`bibiman` offers the possibility to create new citekeys from the fields of +BibLaTeX entries. This is done using an easy but powerful pattern-matching +syntax. + +## Settings<a name="settings"></a> + +All settings for the citekey generation have to be configured in the used config +file. The regular path is `XDG_CONFIG_DIR/bibiman/bibiman.toml`. But it can be +set dynamically with the `-c`/`--config=` global option. + +Following values can be set through the config file. A detailed explanation for +all fields follows below: + +```toml +[citekey_formatter] +fields = [ "author;2;;-;_", "title;3;6;_;_", "year" ] +case = "lowercase" +ascii_only = true +ignored_chars = [ + "?", "!", "\\", "\'", ".", "-", "–", ":", ",", "[", "]", "(", ")", "{", "}", "§", "$", "%", "&", "/", "`", "´", "#", "+", "*", "=", "|", "<", ">", "^", "°", "_", "\"", +] +ignored_words = [ + "the", + "a", + "an", + "of", + "for", + "in", + "at", + "to", + "and", + "der", + "die", + "das", + "ein", + "eine", + "eines", + "des", + "auf", + "und", + "für", + "vor", +] +``` + +## Building Patterns<a name="building-patterns"></a> + +The main aspect for generating citekeys are the field patterns. They can be set +through an array in the config file where every array-item represents a single +BibLaTeX field to be used for generating a part of the citekey. + +Every field pattern consists of the following five parts separated by +semicolons. The general pattern looks like this (every subfield is explained +below): + +*biblatex field name* **;** *max word count* **;** *max char count* **;** *inner +delimiter* **;** *trailing delimiter* + +- **BibLaTeX field**: the first part represents the field name which value + should be used to generate the content part of the citekey. Theoretically, any + BibLaTeX field can be selected by name. But there are some fields which are + much more common than others; e.g. `author`, `editor`, `title`, `year`/`date` + or `entrytype`. Those very common fields are preprocessed; meaning that for + instance LaTeX macros are fully stripped from the strings, or that `editor` is + a fallback value for `author` if the latter is empty (however, setting + `editor` explicitly is still possible). Also using `year` will parse the + `date` field too, to ensure a year number. +- **Max Word**: Defines how many words should maximal be used from the named + field. E.g. if the title consists of five words, and the max counter is set to + `3` only the first three fields will be used. +- **Max Chars/Word**: Defines how many chars, counting from the start, of each + word will be used to build the citekey. If for instance the value is set to + `5`, only the first five chars of any word will be used. Thus, "archaeology" + would be stripped down to "archa". +- **Inner Delimiter**: Sets the delimiter char used between words from the + currently named field; e.g. to separate the words of the `title` field. +- **Trailing Delimiter**: Sets the delimiter which separates the current fields + value from the following. This delimiter is only printed if the following + field has some content. + +For example, to use the `title` field, print maximal three words and of those +only the first five chars, single words separated by underscore and the whole +field separated by equal sign, insert the following pattern field into the +`fields` array: + +`title;3;5;_;=` + +Except the BibLaTeX field name, all other parts of the pattern can be left +blank. If the field name is the only value set, semicolon delimiters are also +not necessary. But if only one of the following parts should be set, all +delimiters need to be used. E.g. those are both valid: `title` or `title;;;_;=`. +The first would print all words of the title, no matter the length, not +separated by any char. The last would also print all words of the title, but +single words separated by underscores and the whole pattern value separated from +the following by an equal sign. This is not valid: `title;;_` since `bibiman` +can't know if the underscore means a delimiter (and which) or the max char +count. + +The pattern array inside the config file takes multiple pattern fields like the +predecing. This allows an elaborated citekey pattern which takes into account +multiple fields. + +## Ignore Lists and Char Case<a name="ignore-lists-and-char-case"></a> + +Beside the field patterns there are some other options to define how citekeys +should be built. + +`ascii_only=<BOOL>` +: If set to `true`, which is the default, non-ascii chars are mapped to their + ascii equivalent. For example, the German `ä` would be mapped to `a`. The + Turkish `ş` or Greek `σ`/`ς` would be mapped to `s`. If set to `false` all are + kept as they are. But this could lead to errors running LaTeX on the file. + +`case=<CASE>` +: If used, sets the case of the chars in the citekey. Valid values are + `uppercase`, `lowercase` or `camelcase`. Both first should be clear, the + latter means typical camel case also beginning the *first word* with an + uppercase letter; also referenced as upper camel case or Pascal case. + +`ignored_chars=<ARRAY>` +: Defines chars which should be ignored during parsing (meaning not print them). + The default list contains 33 special chars and is part of the default config + file (in out-commented state). Be aware, setting this key will completely + overwrite the default list! + +`ignored_words=<ARRAY>` +: A list of words which should be ignored parsing field values. The default list + contains about 20 very commonly used words in English and German; like + articles, pronouns or connector words. Like with `ignored_chars` setting this + key will completely overwrite the default list! + +## General Tipps<a name="general-tipps"></a> + +- Most importantly: *always use the **`--dry-run`** option first*! This will + print a list of old and new values for all citekeys in the file without + changing anything. For the test file of this repo and using the pattern from + the [section below](#examples) `--dry-run` produces the following output: + [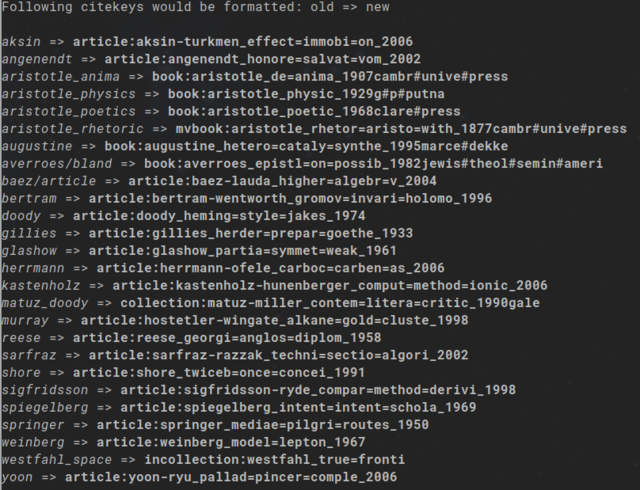](https://postimg.cc/bs4pRJmX) +- After finding a good overall pattern, *use the `--output=` option* to create a + new file and don't overwrite your existing file. Thus, your original file + isn't broken if the key formatter produces some unwanted output. +- Its possible to update citekey based PDF and note files directly when + formatting the citekeys using the `-u`/`--update-attachments` option. Thus, + all PDFs and notes are already linked to the correct entries after updating + the citekeys. Since this operation can break things, use it with `--dry-run` + first. As with regular citekeys this will print all changes without processing + anything. +- Even very long patterns are possible, they are not encouraged, since it bloats + the bibfiles. +- The same accounts for *too short* patterns; if the pattern is to unspecific, + it bares the risk of producing doublettes (e.g. single author and year only). + But the citekey generator will not check for doublettes! +- It is possible to keep special chars and use them as delimiters. But this + might cause problems for other programs and CLI tools in particular, since + many special chars are reserved for shell operations. For instance, it will + very likely break the note file feature of `bibiman` which doesn't accept many + special chars. + +## Examples<a name="examples"></a> + +To make the process more clear a few examples might help. Following bibfile is +assumed: + +```latex +@article{Bos2023, + title = {{LaTeX}, metadata, and publishing workflows}, + author = {Bos, Joppe W. and {McCurley}, Kevin S.}, + year = {2023}, + month = apr, + journal = {arXiv}, + number = {{arXiv}:2301.08277}, + doi = {10.48550/arXiv.2301.08277}, + url = {http://arxiv.org/abs/2301.08277}, + urldate = {2023-08-22}, + note = {type: article}, +} +@book{Bhambra2021, + title = {Colonialism and \textbf{Modern Social Theory}}, + author = {Bhambra, Gurminder K. and Holmwood, John}, + location = {Cambridge and Medford}, + publisher = {Polity Press}, + date = {2021}, + +``` + +And the following values set in the config file: + +```toml +fields = [ + # Just print the whole entrytype and a colon as trailing delimiter + "entrytype;;;;:", + # Print all author names in full length, names separated by dash, + # the whole field by underscore + "author;;;-;_", + # Print first 4 words of title, first 3 chars of every word only. Title words + # separated by equal sign, the whole field by underscore + "title;4;3;=;_", + # Print all words of location, but only first 4 chars of every word. Single words + # separated by colon, whole field by underscore + "location;;4;:;_", + # Just print the whole year + "year", +] +case = "lowercase" +ascii_only = true +``` + +The combination of those setting will produce the following citekeys: + +- **`article:bos-mccurley_lat=met=pub=wor_2023`** +- **`book:bhambra-holmwood_col=mod=soc=the_camb:medf_2021`** + +**Personal Note** + +I use the following pattern to format the citekeys of my bibfiles: + +```toml +[citekey_formatter] +fields = [ + "author;1;;;_", + "title;3;7;-;_", + "year;;;;_", + "entrytype;;;;_", + "shorthand", +] +case = "lowercase" +ascii_only = true +``` + +It produces citekeys with enough information to quickly identify the underlying +work while not being too long; at least in my opinion. The shorthand at the end +is only printed in a few cases, but shows me that the specific work might differ +from standard articles/books etc. @@ -103,10 +103,12 @@ dependencies = [ "biblatex", "color-eyre", "crossterm", + "deunicode", "dirs", "editor-command", "figment", "futures", + "indoc", "itertools", "lexopt", "logos", @@ -323,6 +325,12 @@ dependencies = [ ] [[package]] +name = "deunicode" +version = "1.6.2" +source = "registry+https://github.com/rust-lang/crates.io-index" +checksum = "abd57806937c9cc163efc8ea3910e00a62e2aeb0b8119f1793a978088f8f6b04" + +[[package]] name = "dirs" version = "5.0.1" source = "registry+https://github.com/rust-lang/crates.io-index" @@ -8,7 +8,7 @@ readme = "README.md" description = "TUI for interacting with BibLaTeX databases" keywords = ["tui", "biblatex", "bibliography", "bibtex", "latex"] categories = ["command-line-utilities"] -edition = "2021" +edition = "2024" exclude = ["/tests", ".*"] [profile.release-git] @@ -40,6 +40,8 @@ figment = { version = "0.10.19", features = [ "toml", "test" ]} owo-colors = "4.2.2" logos = "0.15.1" phf = { version = "0.13.1", features = ["macros"] } +indoc = "2.0.6" +deunicode = "1.6.2" [workspace.metadata.cross.target.aarch64-unknown-linux-gnu] # Install libssl-dev:arm64, see <https://github.com/cross-rs/cross/blob/main/docs/custom_images.md#adding-dependencies-to-existing-images> @@ -9,3 +9,9 @@ pre-build = [ "dpkg --add-architecture $CROSS_DEB_ARCH", "apt-get update && apt-get install --assume-yes libssl-dev:$CROSS_DEB_ARCH", ] + +[target.x86_64-unknown-freebsd] +# pre-build = [ +# "dpkg --add-architecture $CROSS_DEB_ARCH", +# "apt-get update && apt-get install --assume-yes libssl-dev:$CROSS_DEB_ARCH", +# ] @@ -24,9 +24,11 @@ - [Ubuntu/Debian](#ubuntudebian) - [Void Linux](#void-linux) - [Usage](#usage) + - [CLI for citekey formatting](#cli-for-citekey-formatting) - [Configuration](#configuration) - [Location of Config File](#location-of-config-file) - [General Configuration](#general-configuration) + - [Citekey formatting](#citekey-formatting) - [Color Configuration](#color-configuration) - [Features](#features) - [Keybindings](#keybindings) @@ -196,6 +198,13 @@ bibman tests/multi-files/ bibiman tests/biblatex-test.bib tests/multi-files/ ``` +### CLI for citekey formatting<a name="cli-for-citekey-formatting"></a> + +Beside the TUI `bibiman` can format and replace citekeys. To make use of this +feature run the program with the `format-citekeys` subcommand. For more +information use `bibiman format-citekeys --help` and the see +[docs](./CITEKEYS.md). + ## Configuration<a name="configuration"></a> ### Location of Config File<a name="location-of-config-file"></a> @@ -268,6 +277,11 @@ note_symbol = "" ## Possible values are "journaltitle", "organization", "instituion", "publisher" ## and "pubtype" (which is the default) custom_column = "pubtype" + +[citekey_formatter] +fields = [] +ascii_only = true +case = "lowercase" ``` `bibfiles` @@ -326,6 +340,12 @@ custom_column = "pubtype" good advice to use a rather wide terminal window when using a value like `journaltitle`. +### Citekey formatting<a name="citekey-formatting"></a> + +`bibiman` now also offers a citekey generating feature. This enables to reformat +all citekeys based on an elaborated pattern matching syntax. For furthter +information and examples see the [docs](CITEKEYS.md). + ### Color Configuration<a name="color-configuration"></a> Furthermore, it is now possible to customize the colors. The following values diff --git a/src/bibiman.rs b/src/bibiman.rs index c423ce1..392ae95 100644 --- a/src/bibiman.rs +++ b/src/bibiman.rs @@ -16,22 +16,23 @@ ///// use crate::app::expand_home; +use crate::bibiman::citekeys::CitekeyFormatting; use crate::bibiman::entries::EntryTableColumn; use crate::bibiman::{bibisetup::*, search::BibiSearch}; use crate::cliargs::CLIArgs; use crate::config::BibiConfig; -use crate::tui::popup::{PopupArea, PopupItem, PopupKind}; use crate::tui::Tui; +use crate::tui::popup::{PopupArea, PopupItem, PopupKind}; use crate::{app, cliargs}; use crate::{bibiman::entries::EntryTable, bibiman::keywords::TagList}; use arboard::Clipboard; -use color_eyre::eyre::{Context, Error, Result}; +use biblatex::Bibliography; +use color_eyre::eyre::{Context, Error, Result, eyre}; use crossterm::event::KeyCode; use editor_command::EditorBuilder; use ratatui::widgets::ScrollbarState; -use regex::Regex; use std::ffi::OsStr; -use std::fs::{self, read_to_string}; +use std::fs::{self}; use std::fs::{File, OpenOptions}; use std::io::Write; use std::path::PathBuf; @@ -40,6 +41,7 @@ use std::result::Result::Ok; use tui_input::Input; pub mod bibisetup; +pub mod citekeys; pub mod entries; pub mod keywords; pub mod search; @@ -88,13 +90,14 @@ pub struct Bibiman { } impl Bibiman { - // Constructs a new instance of [`App`]. + /// Constructs a new instance of [`Bibiman`]. pub fn new(args: &mut CLIArgs, cfg: &mut BibiConfig) -> Result<Self> { let mut main_bibfiles: Vec<PathBuf> = args.pos_args.clone(); if cfg.general.bibfiles.is_some() { main_bibfiles.append(cfg.general.bibfiles.as_mut().unwrap()) }; let main_bibfiles = cliargs::parse_files(main_bibfiles); + // TODO: insert workflow for formatting citekeys let main_biblio = BibiSetup::new(&main_bibfiles, cfg); let tag_list = TagList::new(main_biblio.keyword_list.clone()); let search_struct = BibiSearch::default(); @@ -188,7 +191,9 @@ impl Bibiman { self.popup_area.popup_message = message.unwrap().to_owned(); Ok(()) } else { - Err(Error::msg("You need to past at least a message via Some(&str) to create a message popup")) + Err(Error::msg( + "You need to past at least a message via Some(&str) to create a message popup", + )) } } PopupKind::MessageError => { @@ -200,7 +205,9 @@ impl Bibiman { self.popup_area.popup_message = message.unwrap().to_owned(); Ok(()) } else { - Err(Error::msg("You need to past at least a message via Some(&str) to create a message popup")) + Err(Error::msg( + "You need to past at least a message via Some(&str) to create a message popup", + )) } } PopupKind::OpenRes => { @@ -678,23 +685,32 @@ impl Bibiman { // Index of selected popup field let popup_idx = self.popup_area.popup_state.selected().unwrap(); - // regex pattern to match citekey in fetched bibtexstring - let pattern = Regex::new(r"\{([^\{\},]*),").unwrap(); + let new_bib_entry = Bibliography::parse(&self.popup_area.popup_sel_item) + .map_err(|e| eyre!("Couldn't parse downloaded bib entry: {}", e.to_string()))?; - let citekey = pattern - .captures(&self.popup_area.popup_sel_item) - .unwrap() - .get(1) - .unwrap() - .as_str() - .to_string(); + let formatted_struct = + if let Some(formatter) = CitekeyFormatting::new(cfg, new_bib_entry.clone()) { + Some(formatter.do_formatting()) + } else { + None + }; + + let (new_citekey, entry_string) = if let Some(mut formatter) = formatted_struct { + ( + formatter.get_citekey_pair(0).unwrap().1, + formatter.print_updated_bib_as_string(), + ) + } else { + let keys = new_bib_entry.keys().collect::<Vec<&str>>(); + (keys[0].to_string(), new_bib_entry.to_biblatex_string()) + }; // Check if new file or existing file was choosen let mut file = if self.popup_area.popup_list[popup_idx] .0 .contains("Create new file") { - let citekey = PathBuf::from(&citekey); + let citekey = PathBuf::from(&new_citekey); // Get path of current files let path: PathBuf = if self.main_bibfiles[0].is_file() { self.main_bibfiles[0].parent().unwrap().to_owned() @@ -712,45 +728,18 @@ impl Bibiman { } else { let file_path = &self.main_bibfiles[popup_idx - 1]; - // Check if similar citekey already exists - let file_string = read_to_string(&file_path).unwrap(); - - // If choosen file contains entry with fetched citekey, append an - // char to the citekey so no dublettes are created - if file_string.contains(&citekey) { - let mut new_citekey = String::new(); - - // Loop over ASCII alpabetic chars and check again if citekey with - // appended char exists. If yes, move to next char and test again. - // If the citekey is free, use it and break the loop - for c in b'a'..=b'z' { - let append_char = (c as char).to_string(); - new_citekey = citekey.clone() + &append_char; - if !file_string.contains(&new_citekey) { - break; - } - } - - let new_entry_string_clone = self.popup_area.popup_sel_item.clone(); - - // Replace the double citekey with newly created - self.popup_area.popup_sel_item = pattern - .replace(&new_entry_string_clone, format!("{{{},", &new_citekey)) - .to_string(); - } - OpenOptions::new().append(true).open(file_path).unwrap() }; // Optionally, add a newline before the content file.write_all(b"\n")?; // Write content to file - file.write_all(self.popup_area.popup_sel_item.as_bytes())?; + file.write_all(entry_string.as_bytes())?; // Update the database and the lists to reflect the new content self.update_lists(cfg); self.close_popup(); // Select newly created entry - self.select_entry_by_citekey(&citekey); + self.select_entry_by_citekey(&new_citekey); Ok(()) } @@ -1283,38 +1272,10 @@ impl Bibiman { #[cfg(test)] mod tests { - use regex::Captures; - - use super::*; - #[test] fn citekey_pattern() { let citekey = format!("{{{},", "a_key_2001"); assert_eq!(citekey, "{a_key_2001,") } - - #[test] - fn regex_capture_citekey() { - let re = Regex::new(r"\{([^\{\},]*),").unwrap(); - - let bibstring = String::from("@article{citekey77_2001:!?, author = {Hanks, Tom}, title = {A great book}, year = {2001}}"); - - let citekey = re.captures(&bibstring).unwrap().get(1).unwrap().as_str(); - - assert_eq!(citekey, "citekey77_2001:!?"); - - if bibstring.contains(&citekey) { - let append_char = "a"; - let new_entry_string_clone = bibstring.clone(); - - let updated_bibstring = re - .replace(&new_entry_string_clone, |caps: &Captures| { - format!("{{{}{},", &caps[1], &append_char) - }) - .to_string(); - - assert_eq!(updated_bibstring, "@article{citekey77_2001:!?a, author = {Hanks, Tom}, title = {A great book}, year = {2001}}") - } - } } diff --git a/src/bibiman/bibisetup.rs b/src/bibiman/bibisetup.rs index b3f788c..a817236 100644 --- a/src/bibiman/bibisetup.rs +++ b/src/bibiman/bibisetup.rs @@ -22,6 +22,7 @@ use itertools::Itertools; use serde::{Deserialize, Serialize}; use std::collections::HashMap; use std::ffi::{OsStr, OsString}; +use std::path::Path; use std::{fs, path::PathBuf}; use walkdir::WalkDir; @@ -246,8 +247,14 @@ impl BibiData { } impl BibiSetup { + /// Setup the TUI: + /// * Getting files + /// * Parse files into `biblatex::Bibliography` struct + /// * If wanted, format citekeys + /// * Get citekey vector + /// * Collect all keywords + /// * Build the entry list to be displayed pub fn new(main_bibfiles: &[PathBuf], cfg: &BibiConfig) -> Self { - // TODO: Needs check for config file path as soon as config file is impl Self::check_files(main_bibfiles); let bibfilestring = Self::bibfiles_to_string(main_bibfiles); let bibliography = biblatex::Bibliography::parse(&bibfilestring).unwrap(); @@ -264,7 +271,7 @@ impl BibiSetup { } } - // Check which file format the passed file has + /// Check which file format the passed file has fn check_files(main_bibfiles: &[PathBuf]) { if main_bibfiles.is_empty() { println!( @@ -312,23 +319,27 @@ impl BibiSetup { cfg: &BibiConfig, ) -> Vec<BibiData> { let mut pdf_files = if cfg.general.pdf_path.is_some() { - collect_file_paths(cfg.general.pdf_path.as_ref().unwrap(), &Some(vec!["pdf"])) + collect_file_paths( + cfg.general.pdf_path.as_ref().unwrap(), + Some(vec!["pdf".into()].as_slice()), + ) + } else { + None + }; + let ext = if let Some(ext) = &cfg.general.note_extensions + && cfg.general.note_path.is_some() + { + // let mut ext: Vec<&str> = Vec::new(); + // for e in cfg.general.note_extensions.as_ref().unwrap().iter() { + // ext.push(e); + // } + Some(ext.as_slice()) } else { None }; - let ext: Option<Vec<&str>> = - if cfg.general.note_path.is_some() && cfg.general.note_extensions.is_some() { - let mut ext: Vec<&str> = Vec::new(); - for e in cfg.general.note_extensions.as_ref().unwrap().iter() { - ext.push(e); - } - Some(ext) - } else { - None - }; let mut note_files = if cfg.general.note_path.is_some() && cfg.general.note_extensions.is_some() { - collect_file_paths(cfg.general.note_path.as_ref().unwrap(), &ext) + collect_file_paths(cfg.general.note_path.as_ref().unwrap(), ext.clone()) } else { None }; @@ -363,7 +374,7 @@ impl BibiSetup { file_field: filepaths.1, subtitle: Self::get_subtitle(k, bibliography), notes: if note_files.is_some() { - Self::get_notepath(k, &mut note_files, &ext) + Self::get_notepath(k, &mut note_files, ext) } else { None }, @@ -569,18 +580,18 @@ impl BibiSetup { ) -> (Option<Vec<OsString>>, bool) { if biblio.get(citekey).unwrap().file().is_ok() { ( - Some(vec![biblio - .get(citekey) - .unwrap() - .file() - .unwrap() - .trim() - .into()]), + Some(vec![ + biblio.get(citekey).unwrap().file().unwrap().trim().into(), + ]), true, ) } else if pdf_files.is_some() { ( - Self::merge_filepath_or_none_two(&citekey, pdf_files, vec!["pdf"]), + Self::merge_filepath_or_none_two( + &citekey, + pdf_files, + vec!["pdf".into()].as_slice(), + ), false, ) } else { @@ -591,10 +602,10 @@ impl BibiSetup { pub fn get_notepath( citekey: &str, note_files: &mut Option<HashMap<String, Vec<PathBuf>>>, - ext: &Option<Vec<&str>>, + ext: Option<&[String]>, ) -> Option<Vec<OsString>> { if let Some(e) = ext { - Self::merge_filepath_or_none_two(citekey, note_files, e.to_vec()) + Self::merge_filepath_or_none_two(citekey, note_files, e) } else { None } @@ -621,7 +632,7 @@ impl BibiSetup { fn merge_filepath_or_none_two( citekey: &str, files: &mut Option<HashMap<String, Vec<PathBuf>>>, - extensions: Vec<&str>, + extensions: &[String], ) -> Option<Vec<OsString>> { let mut file = Vec::new(); @@ -639,11 +650,7 @@ impl BibiSetup { } } - if file.is_empty() { - None - } else { - Some(file) - } + if file.is_empty() { None } else { Some(file) } } } @@ -657,15 +664,17 @@ impl BibiSetup { /// /// Passing [`None`] as argument for extensions will result in collecting all files /// from the given directory and its subdirectories! -pub fn collect_file_paths( - file_dir: &PathBuf, - extensions: &Option<Vec<&str>>, +pub fn collect_file_paths<P: AsRef<Path>>( + file_dir: P, + extensions: Option<&[String]>, ) -> Option<HashMap<String, Vec<PathBuf>>> { let mut files: HashMap<String, Vec<PathBuf>> = HashMap::new(); + let file_dir = file_dir.as_ref(); + // Expand tilde to /home/user let file_dir = if file_dir.starts_with("~") { - &app::expand_home(&file_dir) + &app::expand_home(&file_dir.to_path_buf()) } else { file_dir }; @@ -676,13 +685,13 @@ pub fn collect_file_paths( let f = file.unwrap().into_path(); if f.is_file() && f.extension().is_some() - && extensions.as_ref().is_some_and(|v| { + && extensions.is_some_and(|v| { v.contains( &f.extension() .unwrap_or_default() .to_ascii_lowercase() - .to_str() - .unwrap_or_default(), + .to_string_lossy() + .to_string(), ) }) { @@ -715,11 +724,7 @@ pub fn collect_file_paths( } } - if files.is_empty() { - None - } else { - Some(files) - } + if files.is_empty() { None } else { Some(files) } } #[cfg(test)] @@ -753,8 +758,11 @@ mod tests { ], ); - let matches = - BibiSetup::merge_filepath_or_none_two("citekey", &mut Some(files), vec!["md", "pdf"]); + let matches = BibiSetup::merge_filepath_or_none_two( + "citekey", + &mut Some(files), + vec!["md".into(), "pdf".into()].as_slice(), + ); assert_eq!( matches.clone().unwrap().iter().next().unwrap().to_owned(), @@ -764,9 +772,11 @@ mod tests { matches.clone().unwrap().last().unwrap().to_owned(), OsString::from("/one/other/citekey.pdf") ); - assert!(!matches - .clone() - .unwrap() - .contains(&OsString::from("/one/other/citekey2.pdf"))); + assert!( + !matches + .clone() + .unwrap() + .contains(&OsString::from("/one/other/citekey2.pdf")) + ); } } diff --git a/src/bibiman/citekeys.rs b/src/bibiman/citekeys.rs new file mode 100644 index 0000000..fdeed14 --- /dev/null +++ b/src/bibiman/citekeys.rs @@ -0,0 +1,398 @@ +// bibiman - a TUI for managing BibLaTeX databases +// Copyright (C) 2025 lukeflo +// +// This program is free software: you can redistribute it and/or modify +// it under the terms of the GNU General Public License as published by +// the Free Software Foundation, either version 3 of the License, or +// (at your option) any later version. +// +// This program is distributed in the hope that it will be useful, +// but WITHOUT ANY WARRANTY; without even the implied warranty of +// MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the +// GNU General Public License for more details. +// +// You should have received a copy of the GNU General Public License +// along with this program. If not, see <https://www.gnu.org/licenses/>. +///// + +use std::{ + ffi::OsStr, + fs::OpenOptions, + io::Write, + path::{Path, PathBuf}, +}; + +use biblatex::Bibliography; +use color_eyre::eyre::{OptionExt, eyre}; +use lexopt::Arg::{Long, Short}; +use owo_colors::OwoColorize; +use serde::{Deserialize, Serialize}; + +use crate::{ + bibiman::{ + bibisetup::collect_file_paths, + citekeys::citekey_utils::{SKIPPED_ENTRIES, build_citekey, formatting_help}, + }, + config::{BibiConfig, IGNORED_SPECIAL_CHARS, IGNORED_WORDS}, +}; + +mod citekey_utils; + +#[derive(Debug, Clone, PartialEq, Serialize, Deserialize)] +pub enum CitekeyCase { + #[serde(alias = "uppercase", alias = "upper")] + Upper, + #[serde(alias = "lowercase", alias = "lower")] + Lower, + #[serde( + alias = "camel", + alias = "camelcase", + alias = "camel_case", + alias = "uppercamelcase", + alias = "upper_camel_case" + )] + Camel, +} + +#[derive(Debug, Default, Clone)] +pub(crate) struct CitekeyFormatting<'a> { + /// bibfile to replace keys at. The optional fields defines a differing + /// output file to write to, otherwise original file will be overwritten. + bib_entries: Bibliography, + fields: Vec<String>, + case: Option<CitekeyCase>, + old_new_keys_map: Vec<(String, String)>, + dry_run: bool, + ascii_only: bool, + ignored_chars: &'a [char], + ignored_words: &'a [String], +} + +impl<'a> CitekeyFormatting<'a> { + pub(crate) fn parse_citekey_cli( + parser: &mut lexopt::Parser, + cfg: &BibiConfig, + ) -> color_eyre::Result<()> { + let mut formatter = CitekeyFormatting::default(); + let mut source_file = PathBuf::new(); + let mut target_file: Option<PathBuf> = None; + let mut update_files = false; + + formatter.fields = cfg.citekey_formatter.fields.clone().ok_or_eyre(format!( + "Need to define {} correctly in config file", + "citekey pattern fields".red() + ))?; + + formatter.case = cfg.citekey_formatter.case.clone(); + + formatter.ascii_only = cfg.citekey_formatter.ascii_only; + + if formatter.fields.is_empty() { + return Err(eyre!( + "To format all citekeys, you need to provide {} values in the config file", + "fields".bold() + )); + } + while let Some(arg) = parser.next()? { + match arg { + Short('h') | Long("help") => { + formatting_help(); + return Ok(()); + } + Short('d') | Long("dry-run") => formatter.dry_run = true, + Short('s') | Short('f') | Long("source") | Long("file") => { + source_file = parser.value()?.into() + } + Short('t') | Short('o') | Long("target") | Long("output") => { + target_file = Some(parser.value()?.into()) + } + Short('u') | Long("update-attachments") => update_files = true, + _ => return Err(arg.unexpected().into()), + } + } + + let bibstring = std::fs::read_to_string(&source_file)?; + + formatter.bib_entries = Bibliography::parse(&bibstring) + .map_err(|e| eyre!("Couldn't parse bibfile due to {}", e.kind))?; + + formatter.ignored_chars = if let Some(chars) = &cfg.citekey_formatter.ignored_chars { + chars.as_slice() + } else { + IGNORED_SPECIAL_CHARS.as_slice() + }; + + formatter.ignored_words = if let Some(words) = &cfg.citekey_formatter.ignored_words { + words.as_slice() + } else { + &*IGNORED_WORDS.as_slice() + }; + + let mut updated_formatter = formatter.do_formatting().rev_sort_new_keys_by_len(); + + updated_formatter.update_file(source_file, target_file)?; + + if update_files { + updated_formatter.update_notes_pdfs(cfg)?; + } + + Ok(()) + } + + /// Start Citekey formatting with building a new instance of `CitekeyFormatting` + pub fn new(cfg: &'a BibiConfig, bib_entries: Bibliography) -> Option<Self> { + let fields = cfg.citekey_formatter.fields.clone().unwrap_or(Vec::new()); + if fields.is_empty() { + return None; + } + let ignored_chars = if let Some(chars) = &cfg.citekey_formatter.ignored_chars { + chars.as_slice() + } else { + IGNORED_SPECIAL_CHARS.as_slice() + }; + + let ignored_words = if let Some(words) = &cfg.citekey_formatter.ignored_words { + words.as_slice() + } else { + &*IGNORED_WORDS.as_slice() + }; + + Some(Self { + bib_entries, + fields, + case: cfg.citekey_formatter.case.clone(), + old_new_keys_map: Vec::new(), + dry_run: false, + ascii_only: cfg.citekey_formatter.ascii_only, + ignored_chars, + ignored_words, + }) + } + + /// Process the actual formatting. Updated citekeys will be stored in a the + /// `self.old_new_keys_map` vector consisting of pairs (old key, new key). + pub fn do_formatting(mut self) -> Self { + let mut old_new_keys: Vec<(String, String)> = Vec::new(); + for entry in self.bib_entries.iter() { + // Skip specific entries + if SKIPPED_ENTRIES.contains(&entry.entry_type.to_string().to_lowercase().as_str()) { + continue; + } + old_new_keys.push(( + entry.key.clone(), + build_citekey( + entry, + &self.fields, + self.case.as_ref(), + self.ascii_only, + self.ignored_chars, + self.ignored_words, + ), + )); + } + + self.old_new_keys_map = old_new_keys; + + self + } + + /// Write formatted citekeys to bibfile replacing the old keys in all fields + pub fn update_file<P: AsRef<Path>>( + &mut self, + source_file: P, + target_file: Option<P>, + ) -> color_eyre::Result<()> { + if self.dry_run { + println!( + "{}\n", + "Following citekeys would be formatted: old => new" + .bold() + .underline() + .white() + ); + self.old_new_keys_map.sort_by(|a, b| a.0.cmp(&b.0)); + for (old, new) in &self.old_new_keys_map { + println!("{} => {}", old.italic(), new.bold()) + } + } else { + let target_file = if let Some(path) = target_file { + path.as_ref().to_path_buf() + } else { + source_file.as_ref().to_path_buf() + }; + let mut content = std::fs::read_to_string(source_file)?; + + for (old_key, new_key) in self.old_new_keys_map.iter() { + content = content.replace(old_key, new_key); + } + + let mut new_file = OpenOptions::new() + .truncate(true) + .write(true) + .create(true) + .open(target_file)?; + + new_file.write_all(content.as_bytes())?; + } + Ok(()) + } + + /// Sort the vector containing old/new citekey pairs by the length of the latter. + /// That will prevent the replacement longer key parts that equal a full shorter + /// key. + /// + /// You are **very encouraged** to call this method before `update_file()` + /// or `update_notes_pdfs` to prevent replacing citekeys partly which + /// afterwards wont match the pattern anymore. + pub fn rev_sort_new_keys_by_len(mut self) -> Self { + self.old_new_keys_map + .sort_by(|a, b| b.0.len().cmp(&a.0.len())); + self + } + + pub fn update_notes_pdfs(&self, cfg: &BibiConfig) -> color_eyre::Result<()> { + if let Some(pdf_path) = &cfg.general.pdf_path { + self.update_files_by_citekey_basename(pdf_path, vec!["pdf".into()].as_slice())?; + } + if let Some(note_path) = &cfg.general.note_path + && let Some(ext) = &cfg.general.note_extensions + { + self.update_files_by_citekey_basename(note_path, ext.as_slice())?; + } + Ok(()) + } + + fn update_files_by_citekey_basename<P: AsRef<Path>>( + &self, + path: P, + ext: &[String], + ) -> color_eyre::Result<()> { + let files = collect_file_paths(path.as_ref(), Some(ext)); + if self.dry_run { + println!( + "\n{}\n", + "Following paths would be updated:" + .underline() + .bold() + .white() + ) + } + if let Some(mut f) = files { + for (old_key, new_key) in self.old_new_keys_map.iter() { + for e in ext { + let old_basename = old_key.to_owned() + "." + e; + if let Some(item) = f.get_mut(&old_basename) { + for p in item { + let ext = p.extension(); + let basename = new_key.to_owned() + + "." + + ext.unwrap_or(OsStr::new("")).to_str().unwrap_or(""); + let new_name = p + .parent() + .expect("parent expected") + .join(Path::new(&basename)); + if !self.dry_run { + std::fs::rename(p, new_name)?; + } else { + println!( + "{} => {}", + p.display().to_string().italic().dimmed(), + new_name.display().to_string().bold() + ) + } + } + } + } + } + } + Ok(()) + } + + /// Update the `Bibliography` of the `CitekeyFormatting` struct and return + /// it as `String`. + pub fn print_updated_bib_as_string(&mut self) -> String { + let mut content = self.bib_entries.to_biblatex_string(); + for (old_key, new_key) in self.old_new_keys_map.iter() { + content = content.replace(old_key, new_key); + } + content + } + + pub fn get_citekey_pair(&self, idx: usize) -> Option<(String, String)> { + self.old_new_keys_map.get(idx).map(|pair| pair.to_owned()) + } +} + +#[cfg(test)] +mod tests { + use crate::{ + bibiman::citekeys::{CitekeyCase, CitekeyFormatting}, + config::{IGNORED_SPECIAL_CHARS, IGNORED_WORDS}, + }; + use biblatex::Bibliography; + + #[test] + fn format_citekey_test() { + let src = r" + @article{Bos2023, + title = {{LaTeX}, metadata, and publishing workflows}, + author = {Bos, Joppe W. and {McCurley}, Kevin S.}, + year = {2023}, + month = apr, + journal = {arXiv}, + number = {{arXiv}:2301.08277}, + doi = {10.48550/arXiv.2301.08277}, + url = {http://arxiv.org/abs/2301.08277}, + urldate = {2023-08-22}, + note = {type: article}, + } + @book{Bhambra2021, + title = {Colonialism and \textbf{Modern Social Theory}}, + author = {Bhambra, Gurminder K. and Holmwood, John}, + location = {Cambridge and Medford}, + publisher = {Polity Press}, + date = {2021}, + } + "; + let bibliography = Bibliography::parse(src).unwrap(); + let formatting_struct = CitekeyFormatting { + bib_entries: bibliography, + fields: vec![ + "entrytype;;;;:".into(), + "author;;;-;_".into(), + "title;4;3;=;_".into(), + "location;;4;:;_".into(), + "year".into(), + ], + case: Some(CitekeyCase::Lower), + old_new_keys_map: Vec::new(), + dry_run: false, + ascii_only: true, + ignored_chars: &IGNORED_SPECIAL_CHARS, + ignored_words: &IGNORED_WORDS, + }; + let formatting_struct = formatting_struct.do_formatting(); + assert_eq!( + formatting_struct.old_new_keys_map.get(0).unwrap().1, + "article:bos-mccurley_lat=met=pub=wor_2023" + ); + assert_eq!( + formatting_struct.old_new_keys_map.get(1).unwrap().1, + "book:bhambra-holmwood_col=mod=soc=the_camb:medf_2021" + ); + } + + #[test] + fn sorting_appended_citekeys() { + let mut keys: Vec<(String, String)> = vec![ + ("smith2000".into(), "smith_book_2000".into()), + ("smith2000a".into(), "smith_book_2000a".into()), + ("smith2000ab".into(), "smith_book_2000ab".into()), + ]; + keys.sort_by(|a, b| b.1.len().cmp(&a.1.len())); + let mut keys = keys.iter(); + assert_eq!(keys.next().unwrap().1, "smith_book_2000ab"); + assert_eq!(keys.next().unwrap().1, "smith_book_2000a"); + assert_eq!(keys.next().unwrap().1, "smith_book_2000"); + } +} diff --git a/src/bibiman/citekeys/citekey_utils.rs b/src/bibiman/citekeys/citekey_utils.rs new file mode 100644 index 0000000..773a2d2 --- /dev/null +++ b/src/bibiman/citekeys/citekey_utils.rs @@ -0,0 +1,342 @@ +// bibiman - a TUI for managing BibLaTeX databases +// Copyright (C) 2025 lukeflo +// +// This program is free software: you can redistribute it and/or modify +// it under the terms of the GNU General Public License as published by +// the Free Software Foundation, either version 3 of the License, or +// (at your option) any later version. +// +// This program is distributed in the hope that it will be useful, +// but WITHOUT ANY WARRANTY; without even the implied warranty of +// MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the +// GNU General Public License for more details. +// +// You should have received a copy of the GNU General Public License +// along with this program. If not, see <https://www.gnu.org/licenses/>. +///// + +use biblatex::{ChunksExt, Entry, Type}; +use indoc::formatdoc; +use owo_colors::{ + OwoColorize, + colors::{BrightBlue, Green, White}, +}; + +use crate::bibiman::{citekeys::CitekeyCase, sanitize::sanitize_single_string_fully}; + +pub(super) const SKIPPED_ENTRIES: [&str; 2] = ["set", "xdata"]; + +pub(super) fn formatting_help() { + let help = vec![ + formatdoc!( + "{} {}\n", + env!("CARGO_PKG_NAME").fg::<Green>().bold(), + env!("CARGO_PKG_VERSION") + ), + formatdoc!("{}", "USAGE".bold()), + formatdoc!( + "\t{} {} {} {} {}\n", + env!("CARGO_PKG_NAME").fg::<White>().bold(), + "format-citekeys".bold(), + "[OPTIONS]".bold(), + "--source=<SOURCE>".bold(), + "[--output=<TARGET>]".bold() + ), + formatdoc!( + " + \tThis help describes the CLI usage for the citekey formatting + \tfunctionality of bibiman. The definition of patterns how the + \tcitekeys should be formatted must be set in the config file. + \tFor further informations how to use this patterns etc. see: + \t{} + ", + "https://codeberg.org/lukeflo/bibiman/src/branch/main#bibiman" + .italic() + .fg::<BrightBlue>() + ), + formatdoc!("{}", "OPTIONS".bold()), + formatdoc!( + " + \t{} + \tShow this help and exit + ", + "-h, --help".fg::<White>().bold() + ), + formatdoc!( + " + \t{} + \tDon't apply any changes to the named files. Instead print all + \told citekeys and the formatted strings that would have been + \tapplied in the format: {} => {} + ", + "-d, --dry-run".fg::<White>().bold(), + "old_key".italic(), + "new_key".bold() + ), + formatdoc! {" + \t{} + \tThe bibfile for which the citekey formatting should be processed. + \tTakes a path as argument. + ", "-s, -f, --source=<PATH>, --file=<PATH>".fg::<White>().bold()}, + formatdoc!( + " + \t{} + \tThe bibfile to which the updated content should be written. + \tTakes a path as argument. If the file doesn't exist, it will be + \tcreated. + \tIf the argument isn't used, the original file will be {}! + ", + "-t, -o, --target=<PATH>, --output=<PATH>" + .fg::<White>() + .bold(), + "overwritten".italic(), + ), + formatdoc!( + " + \t{} + \tWhen this option is set, bibiman will also rename all PDFs and + \tnotefiles following the bibiman citekey-basename scheme at the + \tlocations set in the config file. This option can break file paths. + \tTry with {} first! + ", + "-u, --update-attachments".fg::<White>().bold(), + "--dry-run".bold() + ), + ]; + let help = help.join("\n"); + println!("{}", help); +} + +/// Build the citekey from the patterns defined in the config file +pub(super) fn build_citekey( + entry: &Entry, + pattern_fields: &[String], + case: Option<&CitekeyCase>, + ascii_only: bool, + ignored_chars: &[char], + ignored_words: &[String], +) -> String { + // mut string the citekey is built from + let mut new_citekey = String::new(); + + // trailing delimiter of previous field + let mut trailing_delimiter: Option<&str> = None; + + // loop over pattern fields process them + 'field_loop: for pattern in pattern_fields.iter() { + // parse single values from pattern field + let (field_name, max_words, max_chars, inner_delimiter, cur_trailing_delimiter) = + split_formatting_pat(pattern); + + // built the part of the citekey from the current pattern field + let formatted_field_str = { + let mut formatted_str = String::new(); + + // preformat the field depending on biblatex value + let field = preformat_field(field_name, entry); + + // split at whitespaces, count fields and set counter for processed + // splits + let split_field = field.split_whitespace(); + let mut words_passed = 0; + let field_count = field.split_whitespace().count(); + + // If there is a trailing delimiter from the previous field, push it + if let Some(del) = trailing_delimiter { + formatted_str = del.to_string(); + }; + + // If the current field isn't empty, set trailing delimiter for + // upcoming loop repitition. If it's empty, start next run of loop + // directly + if !field.is_empty() { + trailing_delimiter = cur_trailing_delimiter; + } else { + continue 'field_loop; + } + + // loop over single parts of current field and add correct delimiter + // process the single slices and add correct delimiter + 'word_loop: for (idx, field_slice) in split_field.enumerate() { + // if the current slice is a common word from the ignore list, + // skip it. + if ignored_words.contains(&field_slice.to_lowercase()) { + continue; + } + + // Create word slice char by char. We need to loop over chars + // instead of a simple bytes index to also catch chars which + // consist of more than one byte (äöüøæ etc...) + let mut word_slice = String::new(); + let word_chars = field_slice.chars(); + let mut counter = 0; + 'char_loop: for mut c in word_chars { + // If camelcase is set, force first char of word to uppercase + if counter == 0 && case == Some(&CitekeyCase::Camel) { + c = c.to_ascii_uppercase() + } + if let Some(len) = max_chars + && counter >= len + { + break 'char_loop; + } + // if a word slice contains a special char, skip it + if ignored_chars.contains(&c) { + continue 'char_loop; + } + // if non-ascii chars should be mapped, check if needed and do it + if let Some(chars) = deunicode::deunicode_char(c) + && ascii_only + { + word_slice.push_str(chars); + counter += chars.len(); + } else { + word_slice.push(c); + counter += 1; + } + } + // Don't count empty slices and don't add delimiter to those + if !word_slice.is_empty() { + formatted_str = formatted_str + &word_slice; + words_passed += 1; + if max_words.is_some_and(|max| max == words_passed) || idx + 1 == field_count { + break 'word_loop; + } else { + formatted_str = formatted_str + inner_delimiter.unwrap_or(""); + } + } else { + continue 'word_loop; + } + } + formatted_str + }; + new_citekey = new_citekey + &formatted_field_str; + } + match case { + Some(CitekeyCase::Lower) => new_citekey.to_lowercase(), + Some(CitekeyCase::Upper) => new_citekey.to_uppercase(), + // otherwise skip, since camelcase is processed in char loop + _ => new_citekey, + } +} + +/// Preformat some fields which are very common to be used in citekeys +pub(super) fn preformat_field(field: &str, entry: &Entry) -> String { + match field { + // Sanitize all macro code from string + "title" => { + sanitize_single_string_fully(&entry.get_as::<String>(field).unwrap_or("".into())) + } + // Get author names. Fall back to editors before setting empty string + "author" => { + if let Ok(authors) = entry.author() { + let mut last_names = String::new(); + for a in authors.iter() { + last_names = last_names + &a.name + " "; + } + last_names + } else if let Ok(editors) = entry.editors() { + let mut last_names = String::new(); + for editortypes in editors.iter() { + for e in editortypes.0.iter() { + last_names = last_names + &e.name + " "; + } + } + last_names + } else { + "".to_string() + } + } + // Get year of date field, fallback to year field + "year" => { + if let Ok(date) = entry.date() { + date.to_chunks().format_verbatim()[..4].to_string() + } else { + entry.get_as::<String>(field).unwrap_or("".into()) + } + } + // Sanitize all macro code from string + "subtitle" => { + sanitize_single_string_fully(&entry.get_as::<String>(field).unwrap_or("".into())) + } + "editor" => { + if let Ok(editors) = entry.editors() { + let mut last_names = String::new(); + for editortypes in editors.iter() { + for e in editortypes.0.iter() { + last_names = last_names + &e.name + " "; + } + } + last_names + } else { + "".to_string() + } + } + "pubtype" | "entrytype" => entry.entry_type.to_string(), + _ => entry.get_as::<String>(field).unwrap_or("".into()), + } +} + +/// Split a formatting pattern of kind +/// `<field>;<word count>;<char count>;<inside delimiter>;<trailing delimiter>`, +/// e.g.: `title;3;3;_;:` will give `("title", 3, 3, "_", ":")` +pub(super) fn split_formatting_pat( + pattern: &str, +) -> ( + &str, + Option<usize>, + Option<usize>, + Option<&str>, + Option<&str>, +) { + let mut splits = pattern.split(';'); + ( + splits + .next() + .expect("Need field value for formatting citekey"), + if let Some(next) = splits.next() + && next.len() > 0 + { + next.parse::<usize>().ok() + } else { + None + }, + if let Some(next) = splits.next() + && next.len() > 0 + { + next.parse::<usize>().ok() + } else { + None + }, + splits.next(), + splits.next(), + ) +} + +#[cfg(test)] +mod test { + use crate::bibiman::citekeys::citekey_utils::split_formatting_pat; + + #[test] + fn split_citekey_pattern() { + let pattern = "title;3;5;_;_"; + + assert_eq!( + split_formatting_pat(pattern), + ("title", Some(3), Some(5), Some("_"), Some("_")) + ); + + let pattern = "year"; + + assert_eq!( + split_formatting_pat(pattern), + ("year", None, None, None, None) + ); + + let pattern = "author;1;;;_"; + assert_eq!( + split_formatting_pat(pattern), + ("author", Some(1), None, Some(""), Some("_")) + ); + } +} diff --git a/src/bibiman/sanitize.rs b/src/bibiman/sanitize.rs index 9ccf4c4..8c1cc43 100644 --- a/src/bibiman/sanitize.rs +++ b/src/bibiman/sanitize.rs @@ -26,12 +26,12 @@ use optimized_sanitize::optimized_sanitize; macro_rules! optimized_sanitize_bibidata { ($bibidata:expr) => { SanitizedBibiData { - title: optimized_sanitize(&$bibidata.title), + title: optimized_sanitize(false, &$bibidata.title), subtitle: match &$bibidata.subtitle { None => None, - Some(subtitle) => Some(optimized_sanitize(subtitle)), + Some(subtitle) => Some(optimized_sanitize(false, subtitle)), }, - abstract_text: optimized_sanitize(&$bibidata.abstract_text), + abstract_text: optimized_sanitize(false, &$bibidata.abstract_text), } }; } @@ -41,3 +41,7 @@ macro_rules! optimized_sanitize_bibidata { pub fn sanitize_one_bibidata(bibidata: &BibiData) -> SanitizedBibiData { optimized_sanitize_bibidata!(bibidata) } + +pub fn sanitize_single_string_fully(input: &str) -> String { + optimized_sanitize(true, input) +} diff --git a/src/bibiman/sanitize/optimized_sanitize.rs b/src/bibiman/sanitize/optimized_sanitize.rs index 336cc56..dff4d32 100644 --- a/src/bibiman/sanitize/optimized_sanitize.rs +++ b/src/bibiman/sanitize/optimized_sanitize.rs @@ -31,6 +31,17 @@ static LOOKUP: phf::Map<&'static str, (&'static str, Option<&'static str>)> = ph r"\textsc" => ("", Some("")), }; +static LOOKUP_CLEAR_ALL: phf::Map<&'static str, (&'static str, Option<&'static str>)> = phf_map! { + r"\mkbibquote" => ("", Some("")), + r"\enquote*" => ("", Some("")), + r"\enquote" => ("", Some("")), + r"\hyphen" => ("", None), + r"\textbf" => ("", Some("")), + r"\textit" => ("", Some("")), + r"\texttt" => ("", Some("")), + r"\textsc" => ("", Some("")), +}; + #[derive(Logos, Debug)] enum Token { #[token("{")] @@ -43,7 +54,12 @@ enum Token { ForcedSpace, } -pub fn optimized_sanitize(input_text: &str) -> String { +pub fn optimized_sanitize(clear_all: bool, input_text: &str) -> String { + let lookup = if clear_all { + &LOOKUP_CLEAR_ALL + } else { + &LOOKUP + }; let mut char_counter: usize = 0; let mut contains_macro: bool = false; for char in input_text.chars() { @@ -87,7 +103,7 @@ pub fn optimized_sanitize(input_text: &str) -> String { } Token::LaTeXMacro => { let texmacro = lex.slice(); - if let Some(x) = LOOKUP.get(&texmacro.trim_end()) { + if let Some(x) = lookup.get(&texmacro.trim_end()) { if let Some(end) = x.1 { bc_up = true; counter_actions.insert(bracket_counter + 1, end); @@ -115,11 +131,17 @@ mod tests { #[test] fn check_sanitization() { let result = optimized_sanitize( + false, r"\mkbibquote {Intention} und \mkbibquote{Intentionen \mkbibquote{sind} \hyphen\ bibquote\hyphen .}", ); assert_eq!( "\"Intention\" und \"Intentionen \"sind\" - bibquote-.\"", result - ) + ); + let result = optimized_sanitize( + true, + r"\mkbibquote {Intention} und \mkbibquote{Intentionen \mkbibquote{sind} \hyphen\ bibquote\hyphen .}", + ); + assert_eq!("Intention und Intentionen sind bibquote.", result) } } diff --git a/src/cliargs.rs b/src/cliargs.rs index 082ecda..e766e77 100644 --- a/src/cliargs.rs +++ b/src/cliargs.rs @@ -15,23 +15,23 @@ // along with this program. If not, see <https://www.gnu.org/licenses/>. ///// -use color_eyre::eyre::Result; use dirs::{config_dir, home_dir}; +use indoc::formatdoc; use lexopt::prelude::*; +use owo_colors::OwoColorize; use owo_colors::colors::css::LightGreen; use owo_colors::colors::*; -use owo_colors::OwoColorize; use std::env; use std::path::PathBuf; use walkdir::WalkDir; use crate::app; +use crate::bibiman::citekeys::CitekeyFormatting; +use crate::config::BibiConfig; // struct for CLIArgs #[derive(Debug, Default, Clone)] pub struct CLIArgs { - pub helparg: bool, - pub versionarg: bool, pub pos_args: Vec<PathBuf>, pub cfg_path: Option<PathBuf>, pub light_theme: bool, @@ -39,9 +39,16 @@ pub struct CLIArgs { } impl CLIArgs { - pub fn parse_args() -> Result<CLIArgs, lexopt::Error> { + /// This struct parses the command line and initializes and returns the + /// necessary structs `CLIArgs` and `BibiConfig`. + /// + /// Additionally, it returns a bool which defines if the TUI should be run + /// or not. The latter is the case for pure CLI processes as `format-citekeys`. + pub fn parse_args() -> color_eyre::Result<(CLIArgs, BibiConfig, bool)> { let mut args = CLIArgs::default(); let mut parser = lexopt::Parser::from_env(); + let mut subcommand = None; + let mut run_tui = true; // Default config args.cfg_path = if config_dir().is_some() { @@ -52,22 +59,77 @@ impl CLIArgs { None }; + // if parser + // .raw_args() + // .is_ok_and(|mut arg| arg.next_if(|a| a == "format-citekeys").is_some()) + // { + // todo!("Format citekeys options"); + // } + while let Some(arg) = parser.next()? { match arg { - Short('h') | Long("help") => args.helparg = true, - Short('v') | Long("version") => args.versionarg = true, + Short('h') | Long("help") => { + println!("{}", help_func()); + std::process::exit(0); + } + Short('v') | Long("version") => { + println!("{}", version_func()); + std::process::exit(0); + } Short('c') | Long("config-file") => args.cfg_path = Some(parser.value()?.parse()?), Long("light-terminal") => args.light_theme = true, Long("pdf-path") => { args.pdf_path = Some(parser.value()?.parse()?); } - // Value(pos_arg) => parse_files(&mut args, pos_arg), - Value(pos_arg) => args.pos_args.push(pos_arg.into()), - _ => return Err(arg.unexpected()), + Value(pos_arg) => { + if args.pos_args.is_empty() { + let value = pos_arg + .into_string() + .unwrap_or_else(|os| os.to_string_lossy().to_string()); + match value.as_str() { + "format-citekeys" => { + subcommand = Some(value); + run_tui = false; + break; + } + _ => { + args.pos_args.push(value.into()); + } + } + } else { + args.pos_args.push(pos_arg.into()); + } + } + _ => return Err(arg.unexpected().into()), } } - Ok(args) + if args + .cfg_path + .as_ref() + .is_some_and(|f| f.try_exists().is_err() || !f.is_file()) + { + BibiConfig::create_default_config(&args); + } + + let mut cfg = if args.cfg_path.is_some() { + BibiConfig::parse_config(&args)? + } else { + BibiConfig::new(&args) + }; + + if let Some(cmd) = subcommand { + match cmd.as_str() { + "format-citekeys" => { + CitekeyFormatting::parse_citekey_cli(&mut parser, &cfg)?; + } + _ => {} + } + } + + cfg.cli_overwrite(&args); + + Ok((args, cfg, run_tui)) } } @@ -121,14 +183,21 @@ pub fn help_func() -> String { env!("CARGO_PKG_VERSION").fg::<LightGreen>(), ), format!( - "{}:\n\t{} [Flags] [files/dirs]\n", + "{}\n\t{} [OPTIONS] [SUBCOMMAND | POSITIONAL ARGUMENTS]\n", "USAGE".bold(), - "bibiman".bold() + env!("CARGO_PKG_NAME").fg::<White>().bold() + ), + formatdoc!( + " + \tYou can either use a {} or {}, not both! + ", + "subcommand".bold(), + "positional arguments".bold() ), format!( - "{}:\n\t{}\t\tPath to {} file", + "{}\n\t{}\t\tPath to {} file", "POSITIONAL ARGUMENTS".bold(), - "<file>".fg::<BrightMagenta>().bold(), + "<file>".fg::<Magenta>().bold(), ".bib".fg::<BrightBlack>().bold() ), format!( @@ -137,38 +206,58 @@ pub fn help_func() -> String { ".bib".fg::<BrightBlack>().bold() ), format!("\n\t{}", "Both can be passed multiple times".italic()), - format!("\n{}:", "FLAGS".bold()), - format!("\t{}", "-h, --help".bold().fg::<BrightCyan>()), - format!("\t\t{}", "Show this help and exit"), - format!("\t{}", "-v, --version".bold().fg::<BrightCyan>()), - format!("\t\t{}", "Show the version and exit"), - format!("\t{}", "--light-terminal".bold().fg::<BrightCyan>()), - format!( - "\t\t{}", - "Enable default colors for light terminal background" + format!("\n{}", "SUBCOMMANDS".bold()), + formatdoc!( + " + \t{} + \tRun the citekey formatting procedure on a specified bibfile. + \tFor further infos run {} + ", + "format-citekeys".fg::<BrightYellow>().bold(), + "bibiman format-citekeys --help".fg::<BrightBlack>().bold() ), - format!( - "\t{}{}", - "-c, --config-file=".bold().fg::<BrightCyan>(), - "<value>".bold().italic().fg::<BrightCyan>() + format!("{}", "OPTIONS".bold()), + formatdoc!( + " + \t{} + \tShow this help and exit + ", + "-h, --help".bold().fg::<White>() ), - format!("\t\t{}", "Path to config file used for current session."), - format!("\t\t{}", "Takes precedence over standard config file."), - format!( - "\t{}{}", - "--pdf-path=".bold().fg::<BrightCyan>(), - "<value>".bold().italic().fg::<BrightCyan>() + formatdoc!( + " + \t{} + \tShow the version and exit + ", + "-v, --version".bold().fg::<White>() ), - format!("\t\t{}", "Path to directory containing PDF files."), - format!( - "\t\t{}", - "If the pdf files basename matches an entrys citekey," + formatdoc!( + " + \t{} + \tEnable default colors for light terminal background + ", + "--light-terminal".bold().fg::<White>() ), - format!( - "\t\t{}", - "its attached as connected PDF file for the current session." + formatdoc!( + " + \t{}{} + \tPath to config file used for current session. + \tTakes precedence over standard config file. + ", + "-c, --config-file=".bold().fg::<White>(), + "<value>".bold().italic().fg::<White>() + ), + formatdoc!( + " + \t{}{} + \tPath to directory containing PDF files. + \tIf the pdf files basename matches an entrys citekey, + \tits attached as connected PDF file for the current session. + \tDoes not edit the bibfile itself! + ", + "--pdf-path=".bold().fg::<White>(), + "<value>".bold().italic().fg::<White>() ), - format!("\t\t{}", "Does not edit the bibfile itself!"), ]; let help = help.join("\n"); help diff --git a/src/config.rs b/src/config.rs index 00a35b7..47e145c 100644 --- a/src/config.rs +++ b/src/config.rs @@ -16,21 +16,65 @@ ///// use std::{ - fs::{create_dir_all, File}, - io::{stdin, Write}, + fs::{File, create_dir_all}, + io::{Write, stdin}, path::PathBuf, str::FromStr, + sync::LazyLock, }; use color_eyre::{eyre::Result, owo_colors::OwoColorize}; use figment::{ - providers::{Format, Serialized, Toml}, Figment, + providers::{Format, Serialized, Toml}, }; use ratatui::style::Color; use serde::{Deserialize, Serialize}; -use crate::{bibiman::bibisetup::CustomField, cliargs::CLIArgs}; +use crate::{ + bibiman::{bibisetup::CustomField, citekeys::CitekeyCase}, + cliargs::CLIArgs, +}; + +pub const IGNORED_SPECIAL_CHARS: [char; 33] = [ + '?', '!', '\\', '\'', '.', '-', '–', ':', ',', '[', ']', '(', ')', '{', '}', '§', '$', '%', + '&', '/', '`', '´', '#', '+', '*', '=', '|', '<', '>', '^', '°', '_', '"', +]; + +pub static IGNORED_WORDS: LazyLock<Vec<String>> = LazyLock::new(|| { + vec![ + String::from("the"), + String::from("a"), + String::from("an"), + String::from("of"), + String::from("for"), + String::from("in"), + String::from("at"), + String::from("to"), + String::from("and"), + String::from("him"), + String::from("her"), + String::from("his"), + String::from("hers"), + String::from("der"), + String::from("die"), + String::from("das"), + String::from("ein"), + String::from("eine"), + String::from("eines"), + String::from("des"), + String::from("auf"), + String::from("und"), + String::from("für"), + String::from("vor"), + String::from("er"), + String::from("sie"), + String::from("es"), + String::from("ihm"), + String::from("ihr"), + String::from("ihnen"), + ] +}); const DEFAULT_CONFIG: &str = r##" # [general] @@ -95,6 +139,55 @@ const DEFAULT_CONFIG: &str = r##" # author_color = "38" # title_color = "37" # year_color = "135" + +# [citekey_formatter] +## Define the patterns for creating citekeys. Every item of the array consists of +## five components separated by semicolons. Despite the field name every component +## can be left blank: +## - name of the biblatex field ("author", "title"...) +## - number of max words from the given field +## - number of chars used from each word +## - delimiter to separate words of the same field +## - trailing delimiter separating the current field from the following +# fields = [ "author;2;;-;_", "title;3;6;_;_", "year" ] + +## Convert chars to specified case. Possible values: +## "upper", "uppercase", "lower", "lowercase" +# case = "lowercase" + +## Map all unicode chars to their pure ascii equivalent +# ascii_only = true + +## List of special chars that'll be ignored when building citekeys. +## A custom list will overwrite the default list +# ignored_chars = [ +# "?", "!", "\\", "\'", ".", "-", "–", ":", ",", "[", "]", "(", ")", "{", "}", "§", "$", "%", "&", "/", "`", "´", "#", "+", "*", "=", "|", "<", ">", "^", "°", "_", """, +# ] + +## List of words that'll be ignored when building citekeys. +## A custom list will overwrite the default list +# ignored_words = [ +# "the", +# "a", +# "an", +# "of", +# "for", +# "in", +# "at", +# "to", +# "and", +# "der", +# "die", +# "das", +# "ein", +# "eine", +# "eines", +# "des", +# "auf", +# "und", +# "für", +# "vor", +# ] "##; /// Main struct of the config file. Contains substructs/headings in toml @@ -102,6 +195,7 @@ const DEFAULT_CONFIG: &str = r##" pub struct BibiConfig { pub general: General, pub colors: Colors, + pub citekey_formatter: CitekeyFormatter, } /// Substruct [general] in config.toml @@ -143,6 +237,15 @@ pub struct Colors { pub year_color: Color, } +#[derive(Debug, Clone, Serialize, Deserialize, PartialEq)] +pub struct CitekeyFormatter { + pub fields: Option<Vec<String>>, + pub case: Option<CitekeyCase>, + pub ascii_only: bool, + pub ignored_chars: Option<Vec<char>>, + pub ignored_words: Option<Vec<String>>, +} + impl Default for BibiConfig { fn default() -> Self { Self { @@ -161,6 +264,13 @@ impl Default for BibiConfig { custom_column: CustomField::Pubtype, }, colors: Self::dark_colors(), + citekey_formatter: CitekeyFormatter { + fields: None, + case: None, + ascii_only: true, + ignored_chars: None, + ignored_words: None, + }, } } } @@ -187,6 +297,13 @@ impl BibiConfig { } else { Self::dark_colors() }, + citekey_formatter: CitekeyFormatter { + fields: None, + case: None, + ascii_only: true, + ignored_chars: None, + ignored_words: None, + }, } } @@ -344,8 +461,8 @@ fn select_opener() -> String { #[cfg(test)] mod tests { use figment::{ - providers::{Format, Toml}, Figment, + providers::{Format, Toml}, }; use super::BibiConfig; @@ -382,6 +499,9 @@ mod tests { author_color = "38" title_color = "37" year_color = "135" + + [citekey_formatter] + ascii_only = true "#, )?; diff --git a/src/main.rs b/src/main.rs index c956d7c..e735eb0 100644 --- a/src/main.rs +++ b/src/main.rs @@ -18,7 +18,6 @@ use app::App; use cliargs::CLIArgs; use color_eyre::eyre::Result; -use config::BibiConfig; use errorsetup::init_error_hooks; pub mod app; @@ -31,41 +30,16 @@ pub mod tui; #[tokio::main] async fn main() -> Result<()> { // Parse CLI arguments - let mut parsed_args = CLIArgs::parse_args()?; + let (mut parsed_args, mut cfg, run_tui) = CLIArgs::parse_args()?; - // Print help if -h/--help flag is passed and exit - if parsed_args.helparg { - println!("{}", cliargs::help_func()); - std::process::exit(0); - } + if run_tui { + init_error_hooks()?; - // Print version if -v/--version flag is passed and exit - if parsed_args.versionarg { - println!("{}", cliargs::version_func()); - std::process::exit(0); - } + // Create an application. + let mut app = App::new(&mut parsed_args, &mut cfg)?; - if parsed_args - .cfg_path - .as_ref() - .is_some_and(|f| !f.try_exists().unwrap() || !f.is_file()) - { - BibiConfig::create_default_config(&parsed_args); + app.run(&cfg).await?; } - let mut cfg = if parsed_args.cfg_path.is_some() { - BibiConfig::parse_config(&parsed_args)? - } else { - BibiConfig::new(&parsed_args) - }; - - cfg.cli_overwrite(&parsed_args); - - init_error_hooks()?; - - // Create an application. - let mut app = App::new(&mut parsed_args, &mut cfg)?; - - app.run(&cfg).await?; Ok(()) } diff --git a/tests/test-config.toml b/tests/test-config.toml index fc447f1..704d8d8 100644 --- a/tests/test-config.toml +++ b/tests/test-config.toml @@ -59,3 +59,22 @@ custom_column = "series" # author_color = "38" # title_color = "37" # year_color = "135" + +[citekey_formatter] +fields = [ + "shorthand;;;;+", + "entrytype;;;;:", + "author;2;;-;_", + "title;3;6;=;_", + "year", + "publisher;;5;#;" +] +# fields = [ # CamelCase test +# "author;2;;;", +# "title;5;5;;", +# "year" +# ] +case = "lowercase" +ascii_only = true +# ignored_words = ["the"] +# ignored_chars = ["?", "."] |