1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
|
# Formatting Citekeys<a name="formatting-citekeys"></a>
<!-- mdformat-toc start --slug=github --maxlevel=6 --minlevel=1 -->
- [Formatting Citekeys](#formatting-citekeys)
- [Settings](#settings)
- [Building Patterns](#building-patterns)
- [Ignore Lists and Char Case](#ignore-lists-and-char-case)
- [General Tipps](#general-tipps)
- [Examples](#examples)
<!-- mdformat-toc end -->
`bibiman` offers the possibility to create new citekeys from the fields of
BibLaTeX entries. This is done using an easy but powerful pattern-matching
syntax.
## Settings<a name="settings"></a>
All settings for the citekey generation have to be configured in the used config
file. The regular path is `XDG_CONFIG_DIR/bibiman/bibiman.toml`. But it can be
set dynamically with the `-c`/`--config=` global option.
Following values can be set through the config file. A detailed explanation for
all fields follows below:
```toml
[citekey_formatter]
fields = [ "author;2;;-;_", "title;3;6;_;_", "year" ]
case = "lowercase"
ascii_only = true
ignored_chars = [
'?', '!', '\\', '\'', '.', '-', '–', ':', ',', '[', ']', '(', ')', '{', '}', '§', '$', '%',
'&', '/', '`', '´', '#', '+', '*', '=', '|', '<', '>', '^', '°', '_', '"', '»', '«', '‘', '’',
'“', '”',
]
ignored_words = [
"the",
"a",
"an",
"of",
"for",
"in",
"at",
"to",
"and",
"der",
"die",
"das",
"ein",
"eine",
"eines",
"des",
"auf",
"und",
"für",
"vor",
]
```
## Building Patterns<a name="building-patterns"></a>
The main aspect for generating citekeys are the field patterns. They can be set
through an array in the config file where every array-item represents a single
BibLaTeX field to be used for generating a part of the citekey.
Every field pattern consists of the following five parts separated by
semicolons. The general pattern looks like this (every subfield is explained
below):
*biblatex field name* **;** *max word count* **;** *max char count* **;** *inner
delimiter* **;** *trailing delimiter*
- **BibLaTeX field**: the first part represents the field name which value
should be used to generate the content part of the citekey. Theoretically, any
BibLaTeX field can be selected by name. But there are some fields which are
much more common than others; e.g. `author`, `editor`, `title`, `year`/`date`
or `entrytype`. Those very common fields are preprocessed; meaning that for
instance LaTeX macros are fully stripped from the strings, or that `editor` is
a fallback value for `author` if the latter is empty (however, setting
`editor` explicitly is still possible). Also using `year` will parse the
`date` field too, to ensure a year number.
- **Max Word**: Defines how many words should maximal be used from the named
field. E.g. if the title consists of five words, and the max counter is set to
`3` only the first three fields will be used.
- **Max Chars/Word**: Defines how many chars, counting from the start, of each
word will be used to build the citekey. If for instance the value is set to
`5`, only the first five chars of any word will be used. Thus, "archaeology"
would be stripped down to "archa".
- **Inner Delimiter**: Sets the delimiter char used between words from the
currently named field; e.g. to separate the words of the `title` field.
- **Trailing Delimiter**: Sets the delimiter which separates the current fields
value from the following. This delimiter is only printed if the following
field has some content.
For example, to use the `title` field, print maximal three words and of those
only the first five chars, single words separated by underscore and the whole
field separated by equal sign, insert the following pattern field into the
`fields` array:
`title;3;5;_;=`
Except the BibLaTeX field name, all other parts of the pattern can be left
blank. If the field name is the only value set, semicolon delimiters are also
not necessary. But if only one of the following parts should be set, all
delimiters need to be used. E.g. those are both valid: `title` or `title;;;_;=`.
The first would print all words of the title, no matter the length, not
separated by any char. The last would also print all words of the title, but
single words separated by underscores and the whole pattern value separated from
the following by an equal sign. This is not valid: `title;;_` since `bibiman`
can't know if the underscore means a delimiter (and which) or the max char
count.
The pattern array inside the config file takes multiple pattern fields like the
predecing. This allows an elaborated citekey pattern which takes into account
multiple fields.
## Ignore Lists and Char Case<a name="ignore-lists-and-char-case"></a>
Beside the field patterns there are some other options to define how citekeys
should be built.
`ascii_only=<BOOL>`
: If set to `true`, which is the default, non-ascii chars are mapped to their
ascii equivalent. For example, the German `ä` would be mapped to `a`. The
Turkish `ş` or Greek `σ`/`ς` would be mapped to `s`. If set to `false` all are
kept as they are. But this could lead to errors running LaTeX on the file.
`case=<CASE>`
: If used, sets the case of the chars in the citekey. Valid values are
`uppercase`, `lowercase` or `camelcase`. Both first should be clear, the
latter means typical camel case also beginning the *first word* with an
uppercase letter; also referenced as upper camel case or Pascal case.
`ignored_chars=<ARRAY>`
: Defines chars which should be ignored during parsing (meaning not print them).
The default list contains 33 special chars and is part of the default config
file (in out-commented state). Be aware, setting this key will completely
overwrite the default list!
`ignored_words=<ARRAY>`
: A list of words which should be ignored parsing field values. The default list
contains about 20 very commonly used words in English and German; like
articles, pronouns or connector words. Like with `ignored_chars` setting this
key will completely overwrite the default list!
## General Tipps<a name="general-tipps"></a>
- Most importantly: *always use the **`--dry-run`** option first*! This will
print a list of old and new values for all citekeys in the file without
changing anything. For the test file of this repo and using the pattern from
the [section below](#examples) `--dry-run` produces the following output:
[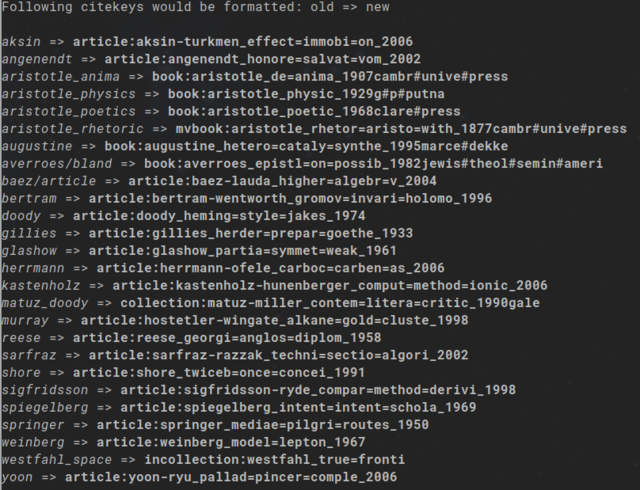](https://postimg.cc/bs4pRJmX)
- After finding a good overall pattern, *use the `--output=` option* to create a
new file and don't overwrite your existing file. Thus, your original file
isn't broken if the key formatter produces some unwanted output.
- Its possible to update citekey based PDF and note files directly when
formatting the citekeys using the `-u`/`--update-attachments` option. Thus,
all PDFs and notes are already linked to the correct entries after updating
the citekeys. Since this operation can break things, use it with `--dry-run`
first. As with regular citekeys this will print all changes without processing
anything.
- Even very long patterns are possible, they are not encouraged, since it bloats
the bibfiles.
- The same accounts for *too short* patterns; if the pattern is to unspecific,
it bares the risk of producing doublettes (e.g. single author and year only).
But the citekey generator will not check for doublettes!
- It is possible to keep special chars and use them as delimiters. But this
might cause problems for other programs and CLI tools in particular, since
many special chars are reserved for shell operations. For instance, it will
very likely break the note file feature of `bibiman` which doesn't accept many
special chars.
## Examples<a name="examples"></a>
To make the process more clear a few examples might help. Following bibfile is
assumed:
```latex
@article{Bos2023,
title = {{LaTeX}, metadata, and publishing workflows},
author = {Bos, Joppe W. and {McCurley}, Kevin S.},
year = {2023},
month = apr,
journal = {arXiv},
number = {{arXiv}:2301.08277},
doi = {10.48550/arXiv.2301.08277},
url = {http://arxiv.org/abs/2301.08277},
urldate = {2023-08-22},
note = {type: article},
}
@book{Bhambra2021,
title = {Colonialism and \textbf{Modern Social Theory}},
author = {Bhambra, Gurminder K. and Holmwood, John},
location = {Cambridge and Medford},
publisher = {Polity Press},
date = {2021},
```
And the following values set in the config file:
```toml
fields = [
# Just print the whole entrytype and a colon as trailing delimiter
"entrytype;;;;:",
# Print all author names in full length, names separated by dash,
# the whole field by underscore
"author;;;-;_",
# Print first 4 words of title, first 3 chars of every word only. Title words
# separated by equal sign, the whole field by underscore
"title;4;3;=;_",
# Print all words of location, but only first 4 chars of every word. Single words
# separated by colon, whole field by underscore
"location;;4;:;_",
# Just print the whole year
"year",
]
case = "lowercase"
ascii_only = true
```
The combination of those setting will produce the following citekeys:
- **`article:bos-mccurley_lat=met=pub=wor_2023`**
- **`book:bhambra-holmwood_col=mod=soc=the_camb:medf_2021`**
**Personal Note**
I use the following pattern to format the citekeys of my bibfiles:
```toml
[citekey_formatter]
fields = [
"author;1;;;_",
"title;3;7;-;_",
"year;;;;_",
"entrytype;;;;_",
"shorthand",
]
case = "lowercase"
ascii_only = true
```
It produces citekeys with enough information to quickly identify the underlying
work while not being too long; at least in my opinion. The shorthand at the end
is only printed in a few cases, but shows me that the specific work might differ
from standard articles/books etc.
|
